As a follow up on my somewhat incoherent rant about developers hiding passwords, keys, and other sensitive information in Android apps, I wanted to go through a semi-realistic example and explain the thought behind some of these strategies and why they may not be as effective as you might initially hope.
While not a comprehensive review, we’ll take a look at the most common secret-stashing strategies (and how it can go wrong):
- Embedded in strings.xml
- Hidden in Source Code
- Hidden in BuildConfigs
- Using Proguard
- Disguised/Encrypted Strings
- Hidden in Native Libraries
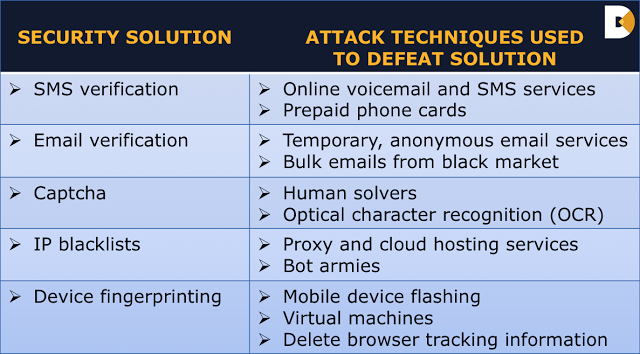
Common Hiding Strategies
To help illustrate some of these concepts, I created an example Android app on Github that we’ll analyze in this post. The full source code is available for review, but be sure to also take a look at the decompiled source. It’s important that you appreciate the perspective of both the developer and the reverse-engineer as you look for potential vulnerabilities.
0. Including Secrets in strings.xml
As an Android developer, your first instinct is probably to include any secrets, such as an API key, in your XML resources as you would with any other assets. We’ve done just that as well in our res/values/strings.xml file:
<string name="app_name">HidingPasswords
<string name="hello_world">Hello world!
<string name="action_settings">Settings
<string name="server_password">My_S3cr3t_P@$$W0rD
While tidy, it’s also probably the easiest to subvert and extract. To see how we can do so, start by downloading our app’s APK- you can download manually from github or using wget from the command line:
$ wget https://github.com/pillfill/hiding-passwords-android/releases/download/1.0/app-x86-universal-debug.apk
Now let’s run strings, the go-to tool finding interesting things in binaries:
$ strings app-x86-universal-debug.apk
…(Lots of output)
You should see all kinds of interesting values here- If you look closely, you’ll even see our key/password included:
$ strings app-x86-universal-debug.apk | grep My
My_S3cr3t_P@$$W0rD
The strings command makes smash-and-grab style API key theft very easy. It works on all kinds of binaries- not just Android apps.
1. Including Secrets in Your Source Code
This is another common starting point for many developers tackling an API integration. To demonstrate, we’ve included a public static final String field and even a byte[] array with our hard-coded keys inside our example app’s MainActivity:
public class MainActivity extends AppCompatActivity {
//A simple static field to store sensitive keys
private static final String myNaivePasswordHidingKey = "My_S3cr3t_P@$$W0rD";
//A marginally better effort to store a key in a byte array (to avoid string analysis)
private static final byte[] mySlightlyCleverHidingKey = new byte[]{
'M','y','_','S','3','c','r','3','t','_','P','@','$','$','W','0','r','D','_','2'
While the strings utility won’t find these quite as easily as with our XML resources, it still can work with a little more digging. Since APKs are actually compressed/zipped files under the covers, We can extact the APK contents and still find both passwords:
$ unzip app-x86-universal-debug.apk
$ strings classes.dex | grep My
My_S3cr3t_P@$$W0rD_2
My_S3cr3t_P@$$W0rD
Again, strings was able to find both values (our password string and byte array!) without breaking a sweat. We told it to look in the classes.dex file- the file that ultimately contains your compiled java code.
2. Including Secrets in Your Build Config
Another suggestion from last week’s Reddit discussion was to manage the key in the BuildConfig from the Android Gradle plugin. There’s definitely some merit to this approach since it
can minimize the risk of leaving secrets exposed in your version control system (especially important if you use a public DVCS like GitHub):
buildTypes {
debug {
minifyEnabled true
buildConfigField "String", "hiddenPassword", "\"${hiddenPassword}\""
}
}
You can then set this value in a .gitignore’d local.properties or a checked-in gradle.properties as shown here:
hiddenPassword=My_S3cr3t_P@$$W0rD
Unfortunately this doesn’t improve on the secret-in-source-code situation described above since these values are emitted as BuildConfig code. It can be inspected and extracted exactly in the same manner.
3. Protecting Secrets with Proguard
So we’re losing the battle with strings. Okay, no problem! We can just throw a little proguard at our app, have it obfuscate our source code, and it should solve our little strings problem. Right?
Not quite. Let’s take a look at proguard-rules.pro in our project:
# Just change our classes (to make things easier)
-keep class !com.apothesource.** { *; }
We’re already telling proguard to obfuscate all of the code in our package (com.apothesource.**). I can also say with confidence that Proguard worked as instructed. So why are we still able to see the passwords?
Proguard explicitly does not do anything to protect or encrypt strings. The reason makes sense too- It can’t just change the value of a string that your app depends on without the risk of significant side effects. You can see exactly what proguard did by reviewing the mapping.txt file in our build output:
com.apothesource.hidingpasswords.HidingUtil -> com.apothesource.hidingpasswords.a:
java.lang.String hide(java.lang.String) -> a
java.lang.String unhide(java.lang.String) -> b
void doHiding(byte[],byte[],boolean) -> a
com.apothesource.hidingpasswords.MainActivity -> .hidingpasswords.MainActivity:
byte[] mySlightlyCleverHidingKey -> a
java.lang.String[] myCompositeKey -> b
So you can see that it renamed our classes, methods, and member/field names as expected. It just didn’t help us at all when it comes to our strings problem. You can also look at the output of the compiler to see the effect of proguard. Here are the normal vs. proguard outputs on our MainActivity static fields, for example:
Normal Output:
#static fields
.field private static final TAG:Ljava/lang/String; = "HidingActivity"
.field private static final myCompositeKey:[Ljava/lang/String;
.field private static final myNaivePasswordHidingKey:Ljava/lang/String; = "My_S3cr3t_P@$$W0rD"
.field private static final mySlightlyCleverHidingKey:[B
Proguard Output:
#static fields
.field private static final n:[B
.field private static final o:[Ljava/lang/String;
Proguard does a good job here of detecting that it can replace variable names and even inline our password to make it a local variable. When you inspect the generated method implementation, though, our password is still there in raw form:
.method public b(Ljava/lang/String;)V
…
move-result-object v0
const-string v1, "My_S3cr3t_P@$$W0rD"
While not a silver bullet, Proguard is still an important tool if you intend to prevent reverse engineering. It is highly effective in stripping valuable context like variable, method, and class names from the compiled output, making detailed analysis tasks much more difficult. If you’d like to compare the decompiled outputs of a proguard vs non-proguard protected application, we’ve included both version of our app on Github.
4. Hiding Your Secret Strings
Since proguard isn’t hiding your strings, why not do it yourself?
You can hide secret strings by transforming though various encoding or encrypting methods, base64 being a very common one. In our app, we do this through some lightweight XOR operations:
//A more complicated effort to store the XOR'ed halves of a key (instead of the key itself)
private static final String[] myCompositeKey = new String[]{
"oNQavjbaNNSgEqoCkT9Em4imeQQ=","3o8eFOX4ri/F8fgHgiy/BS47"
};
This is still our My_S3cr3t_P@$$W0rD secret- We’ve just done some hiding by XORing the value with a randomly generated value. You can inspect the simple HidingUtil implementation if you’d like to see how this value was generated. Note that while this naive method generates a random XOR key for each call, there’s no reason you couldn’t use the same key for all values in your app that you’d like to protect.
When you’re ready to use your ‘hidden’ key, you simply reverse the process:
public void useXorStringHiding(String myHiddenMessage) {
byte[] xorParts0 = Base64.decode(myCompositeKey[0],0);
byte[] xorParts1 = Base64.decode(myCompositeKey[1], 0);
byte[] xorKey = new byte[xorParts0.length];
for(int i = 0; i < xorParts1.length; i++){
xorKey[i] = (byte) (xorParts0[i] ^ xorParts1[i]);
}
HidingUtil.doHiding(myHiddenMessage.getBytes(), xorKey, false);
}
While not terribly clever (or optimized), this is a step in the right direction since this effectively neuters the strings-based analysis. This effectively forcing anyone still analyzing your app to now dive deeper, normally involving 1) studying your app’s compiled output to figure out your hiding scheme, and/or 2) attempting to patch your app. The bad news is that neither is particularly difficult to do.
4a. Studying Smali Output
Smali is an assembler/disassembler for Android’s dalvik VM. It disassembles compiled Android dex code into a human-readable syntax. Utilities like APKTool build on smali resulting in a powerful tool to inspect compiled applications, including those from the Google Play Store.
Consider again, for example, our useXorStringHiding method that combines the XOR key components that we described above. Now compare that with the smali instruction generated from APKTool. There are important clues that can quickly indicate our strategy for hiding strings, like our loop to XOR the values:
:goto_0
array-length v5, v3
if-ge v0, v5, :cond_0
aget-byte v5, v2, v0
aget-byte v6, v3, v0
xor-int/2addr v5, v6
int-to-byte v5, v5
aput-byte v5, v4, v0
add-int/lit8 v0, v0, 0x1
goto :goto_0
Even if you’re not fluent in reading the generated instructions, simply knowing that we have an XOR operation involved gives us 90% of what we need to start pulling things apart.
4b. Patching Binaries
Let’s say I didn’t want to or couldn’t figure out the encoding scheme by just studying the above output. What other options do I have?
Plenty. Let’s say that we’re not able to figure out the above loop, but we are pretty confident that the key we want is available at the end of the loop:
invoke-static {v0, v4, v1}, Lcom/apothesource/hidingpasswords/HidingUtil;->a([B[BZ)V
Instead of trying to figure out what permutations we take along the way, we can simply modify the generated instructions to log the values out to the console at the end. While I won’t try to cover all of the nuances of patching binaries here, rest assured that after patching our app with the new logging statement, every key that passes through this method will be dutifully written out to the console, negating all of our hard work.
5. Native C/C++ JNI Secret Hiding
The strategy of moving sensitive operations out of Java and into native libraries was a common mitigation suggested in the /r/androiddev discussion. It certainly is one of the more effective strategies to thwart reverse engineering attempts since it adds several layers of complexity. To demonstrate this approach, our app includes JNI calls to a C custom function that XORs our keys just like we did in our Java-based implementation. The native/JNI hook is in the HidingUtil class:
/**
* Our hook to the JNI hiding method.
* @param plainText Text to hide (XOR key is hard-coded in the JNI app)
* @return A {@link Base64#encode} encoded value of (plainText XOR key)
*/
public native String hide(String plainText);
/**
* Our hook to the JNI unhiding method.
* @param cipherText {@link Base64}-encoded text to unhide(XOR key is hard-coded in the JNI app)
* @return A string with the original plaintext (cipherText XOR key)
*/
public native String unhide(String cipherText);
The C-source for the function isn’t terribly interesting- It’s a C-language rehashing of the our same XOR-based Java functions.
As expected, decompiling the output doesn’t yield anything useful:
.method public native hide(Ljava/lang/String;)Ljava/lang/String;
.end method
.method public native unhide(Ljava/lang/String;)Ljava/lang/String;
.end method
Our native code compiles into platform-specific SharedObject (or .so) libraries. This additional layer of protection comes at a fairly high cost though, especially you’re not using JNI hooks already. Builds and testing becomes significantly more complicated and standard troubleshooting/crash analysis tools won’t work at this level.
Even if you are comfortable attaching a JNI interface to your app for this purpose, it’s also important to remember that it is still not foolproof. Our naive implementation of the C-functions is vulnerable to the same tool that originally gave us such heartburn initially: strings.
$ strings libhidingutil.so | grep My
My_S3cr3t_P@$$W0rD
Back to where we started!
To be fair, I’m not implying that this is the end of the rabbit hole- you can add layers of indirection and string hiding in the native library as well. Just remember that native libraries have their own reverse engineering tools. So long as you hide secrets in the bits you give to your users, rest assured that someone is out there patiently trying to extract them back out.
Summary
The best way to protect secrets is to never reveal them. Compartmentalizing sensitive information and operations on your own backend server/service should always be your first choice. If you do have to consider a hiding scheme, you should do so with the realization that you can only make the reverse engineering process harder (i.e. not impossible) and you will add significant complication to the development, testing, and maintenance of your app in doing so.